[Paper]GAN
우선 GAN을 정리하기에 앞서 생성모델을 이해해야합니다. 기계 학습 모델은 모델의 역할에 따라 크게 분류 모델과 생성 모델로 나뉠 수 있다고 합니다.
Generation Model(생성모델)
여기서 분류 모델(판별자 모델, Discrimnative Model)은 데이터 X가 주어졌을 때 나타나는 레이블 Y가 나타날 조건부확률 P(Y|X)를 직접적으로 반환하는 모델입니다.(주로 고차원의 데이터에서 낮은 차원의 레이블 데이터로 변환하는 작업)
이와 다르게 생성 모델(Generative Model)은 데이터의 분포를 추정하는 방법으로 아래와 같이 두가지로 나뉠 수 있습니다.(주로 분류 모델과는 반대로 낮은 차원에서 높은 차원의 데이터를 만들어내는 작업)
- 지도적 생성모델 : Label이 있는 데이터에 대해 확률분포를 추정한 후 계산하는 방법으로 대표적인 예시로는 선형판별분석법(LDA), 이차판별분석법(QDA)가 있다.
- 비지도적 생성모델 : Label이 없는 데이터에 대한 분포를 학습하여 모분포를 추정하는 방법입니다.
- 통계적 생성 모델 : 관측된 데이터들의 분포로 원래 변수의 확률 분포를 추정하는 밀도 추정 모델이라 볼 수 있다. 대표적인 예시로는 커널 밀도 추정(KDE), 가우시안 밀도 추정 모델 등
- 딥러닝을 이용 생성 모델 :
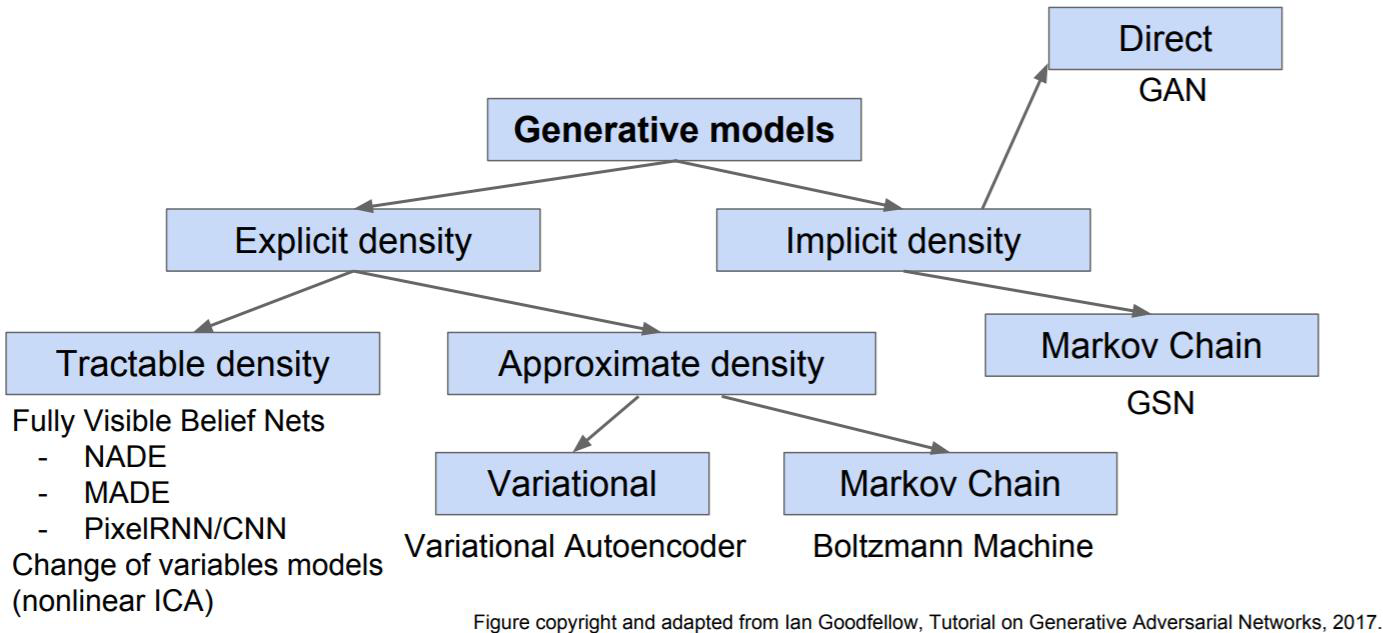 출처 : https://danbi-ncsoft.github.io
출처 : https://danbi-ncsoft.github.io해당 그림을 보면 처음으로 Explicit density와 Implicit density 2가지로 나뉘어 진다.
- Explicit density(명시적) : 확률 변수 p(x)를 정의하여 사용하는 것.
- Tractable density : 데이터를 가지고 확률 분포를 ‘직접’구하는 방법.
- Approximate density : 데이터를 가지고 확률 분포를 ‘추정’하는 방법.(VAE, Variational Auto-Encoder)
- Implicit density(암시적) : 확률 변수 p(x)에 대한 정의 없이 p(x)를 샘플링하여 사용. 대표적으로 GAN이 있음.
GAN(Generative Adversarial Networks)
2014년도에 출판된 논문으로 딥러닝에서 생성 모델링을 위한 혁신적인 접근 방법으로 이미지 생성, 음악 생성, 자연어 처리 등 다양한 분야에서 혁신적인 결과를 이끌어내었습니다.
GAN의 종류
ⅰ. Motivation and Problem Definition
딥러닝의 잠재력은 데이터 종류에 대한 확률 분포를 나타내는 계층적인 모델을 발견하는 것입니다. 지금까지 딥러닝에서 가정 성공한 것은 역전파와 드롭아웃 알고리즘에 기반한 판별(discriminative) 모델일 것입니다. 그에 비해 생성(Generative)모델은 MLE나 관련된 방법으로 발생하는 다루기 힘든 확률적 근사 계산을 근사화 하는 것과 생성문맥 데이터를 얻는 어려움에 의해 덜 발달되었습니다.
따라서, 해당 논문은 Adversarial nets framwork로 생성 모델은 반대되는 적에 대항하여 맞춰지고, 판별모델은 sample이 모델 분포에서 나온 것인지, 데이터 분포에서 나온 것인지를 학습합니다.
직관적으로 생성모델은 위조범과 유사하게 생각할 수 있고 판별모델은 위조범을 찾는 경찰로 생각할 수 있습니다. 해당 구조는 경쟁적인 두 대상이 서로를 향상시켜 서로 진짜를 구별할 수 없는 수준까지 올라가는 형태가 됩니다. 저자는 해당 논문에서 다른 inference나 마코브체인을 필요 없다는 을 강조하였습니다.
ⅱ. Comparison with Related Work
이전 연구나 관련 연구들과의 차이점과 유사점을 분석합니다. 기존 연구의 한계점을 간략히 언급하고, 본 연구의 차별성을 강조합니다.
ⅲ. Method and Model Description
우리는 $D$가 훈련 샘플과 $G$의 샘플을 모두 올바르게 구별하도록 훈련시킨다. 동시에 $G$를 $log(1-D(G(z)))$를 최소화하는 방향으로 훈련시킨다. 즉, $D$와 $G$는 아래와 같이 two-plater minimax game인 가치 함수 $V(G,D)$이 된다.
x: data, z: noise
다음은 적대적 신경망의 이론적 분석을 제시한다.
- Figure 1
- 데이터 생성 분포(검은색 점선)와 생성 모델(녹색 실선)을 판별하도록 판별모델(파란 실선)을 동시에 업데이트 하여 학습된다. 위를 향하는 화살표는 $x=G(z)$를 보여준다. (a) : 화살표가 수렴되는 곳을 보면 $p_g$는 $p_{data}$와 유사하게 보이고 D는 부분적으로 정확하게 분류했다., (b) : $D$의 내부루프에서 샘플들을 판별하기 위해 훈련된다, $D^*(x)= \frac{P_{data}(x)}{P_{data}(x) + P_{g}(x)} $(c) : $G$ 업데이트 이후 $D$의 기울기가 조정된다, (d) : $G$와 $D$의 학습이 충분히 이루어진 후 $p_g = p_{data}$에 근접하므로 $D(x) = 0.5$가 되기에 더이상 구분하지 못한다.
Theoretical Results
- Algorithm 1.
- 미니배치 확률적 경사하강법(SGD).
Global Optimality of $p_g = p_{data}$
- Proposition 1. $G$가 고정되었을때 최적의 $D$는 아래와 같다.
- Proof. $G$가 주어졌을때, $D$의 훈련 기준은 가치함수 $V(G,D)$의 양을 최대화하는 것이다.
- Kullback-Leibler 발산.
- \[KL(p_{data}||p_g) = \int_{\infty}^{-\infty}P_{data}(x)log(\frac{P_{data}(x)}{P_g(x)})\]
- Theorem 1. 가상 훈련 기준 $C(G)$의 전역 최소값은 $p_g = p_{data}$인 경우에만 달성된다.
두 분포 사이의 Jensen-Shannon 발산은 항상 음이 아니고 그것들이 같을 때만 0이기 때문에, 가상 훈련 기준 $C(G)^*=-log(4)$가 전역 최소값이며, $p_g = p_{data}$이 유일한 값이 된다.
Convergence of Algorithm 1.
- Proposition 2.
- $G$, $D$ 모두 충분한 능력을 가지고 있고 Algorithm 1의 각 단계에서 판별자가 최적의 $G$에 도달할 수 있으며 $p_g$는 기준을 개선하기 위해 갱신된다. 그리고 $p_g$는 $p_{data}$로 수렴한다.
- Proof 2.
- $V(G,D) = U(p_g, D)$는 $p_g$에 대해서 convex한 형태를 가지고 있다. $p_g$에 대해 $sup_DU(p_g,D)$가 유일한 전역 최적점을 가지고 있으며 convex 하는 것이 Theorem 1 에서 증명되었기에 $p_g$는 충분히 작게 갱신되고, $p_x$로 수렴하므로 증명을 마무리한다.
ⅳ. Experimental Results
MNIST, the Toronto Face Database (TFD), and CIFAR-10 등의 데이터셋을 이용하여 적대신경망을 훈련시켰다. G는 ractifier linear, sigmoid 활성화 함수를 섞어서, D는 maxout 을 사용하였다. D에는 Dropout이 적용되었다.
Figure 2. 생성된 샘플을 시각화 한것으로. 가장 우측의 노란색 테두리는 모델이 훈련세트를 기억하지 않는다는 것을 나타내기 위해 생성된 샘플과 비슷한 훈련 샘플을 나타낸다.
ⅵ. CONCLUSTION.
 출처 : https://paperswithcode.com/method/gan
출처 : https://paperswithcode.com/method/gan
위조범과 판별자간의 관계로 서로 각각 모방과 판별의 능력을 향상 시켜나가는 관계를 가짐.
GAN의 네트워크
- 생성자 네트워크(generator network)
- 랜덤 백터(잠재 공간의 무작위한 포인트)를 입력으로 받아 이를 합성된 이미지로 디코딩
- 판별자 네트워크(discriminator network)
- 이미지를 랜덤으로 입력으로 받아 훈련 세트에서 온 이미지인지 생성자가 만든 이미지인지 판별
- 생성자 네트워크(generator network)
GAN은 매 단계가 조금씩 전체 공간을 바꾸기 때문에 최적화 과정으로 최솟값을 찾는 것이 어려움. 즉, 적절한 파라미터를 찾고 조정해야함.
REFERENCES.
- 생성모델이란 무엇인가?
- Flow based Generative Models
- What are Diffusion Models?
- Generative Flow with Invertible 1x1 Convolutions
- GAN 모델 개요
- Generative Adversarial Networks
- gan bagan
[[학부생의 딥러닝] GANs WGAN, WGAN-GP : Wassestein GAN(Gradient Penalty)](https://haawron.tistory.com/21) - gan gail generative adversarial limitation lerarning